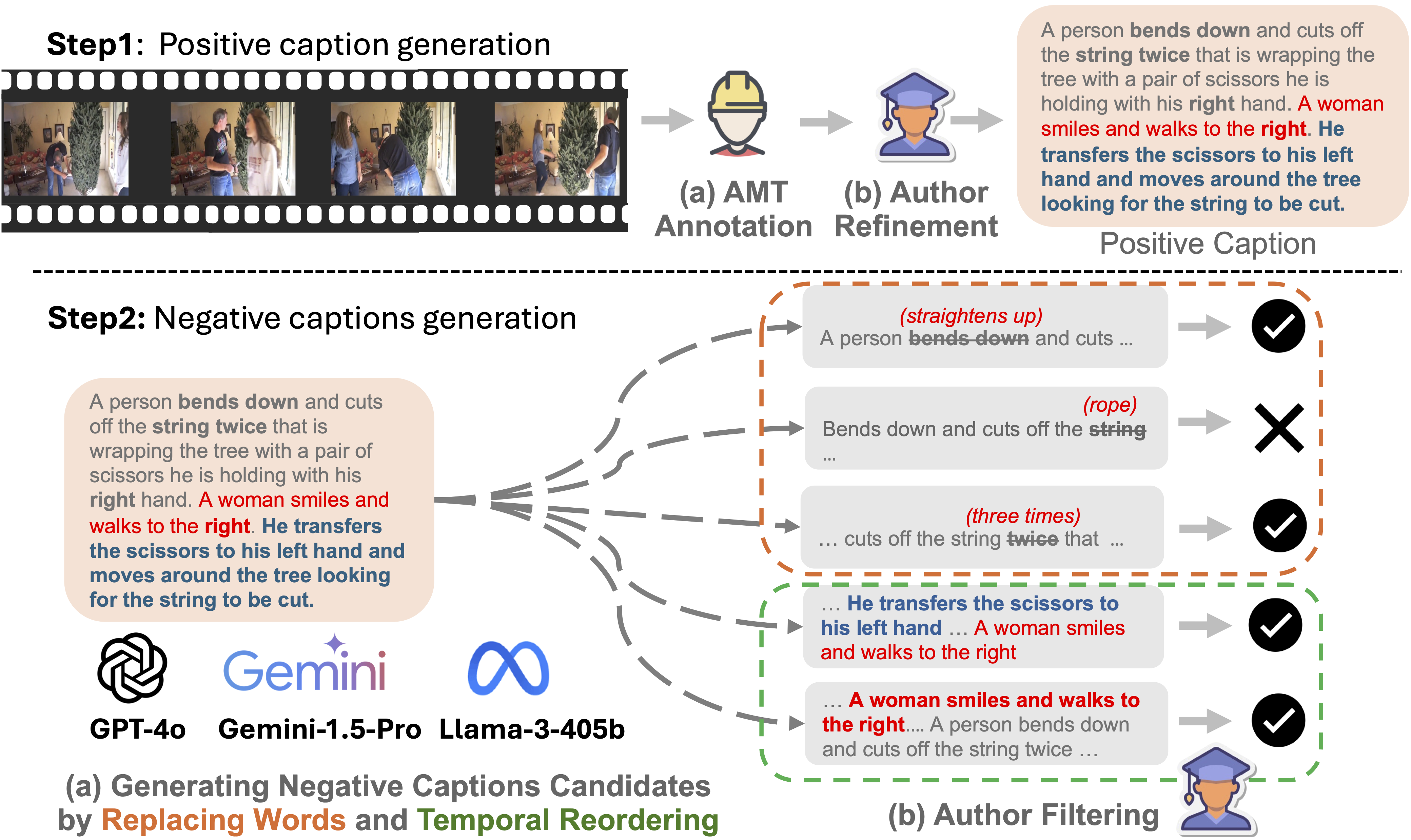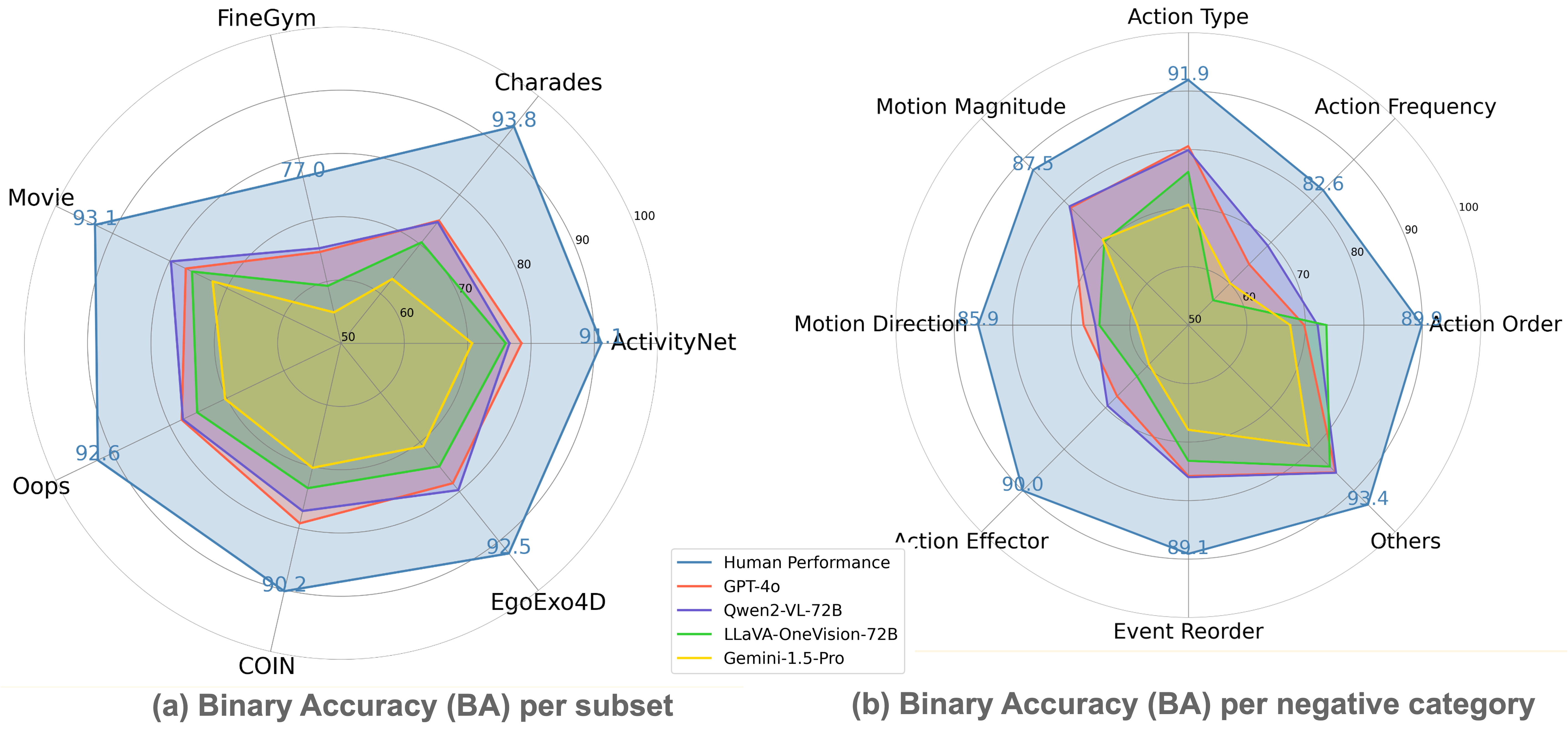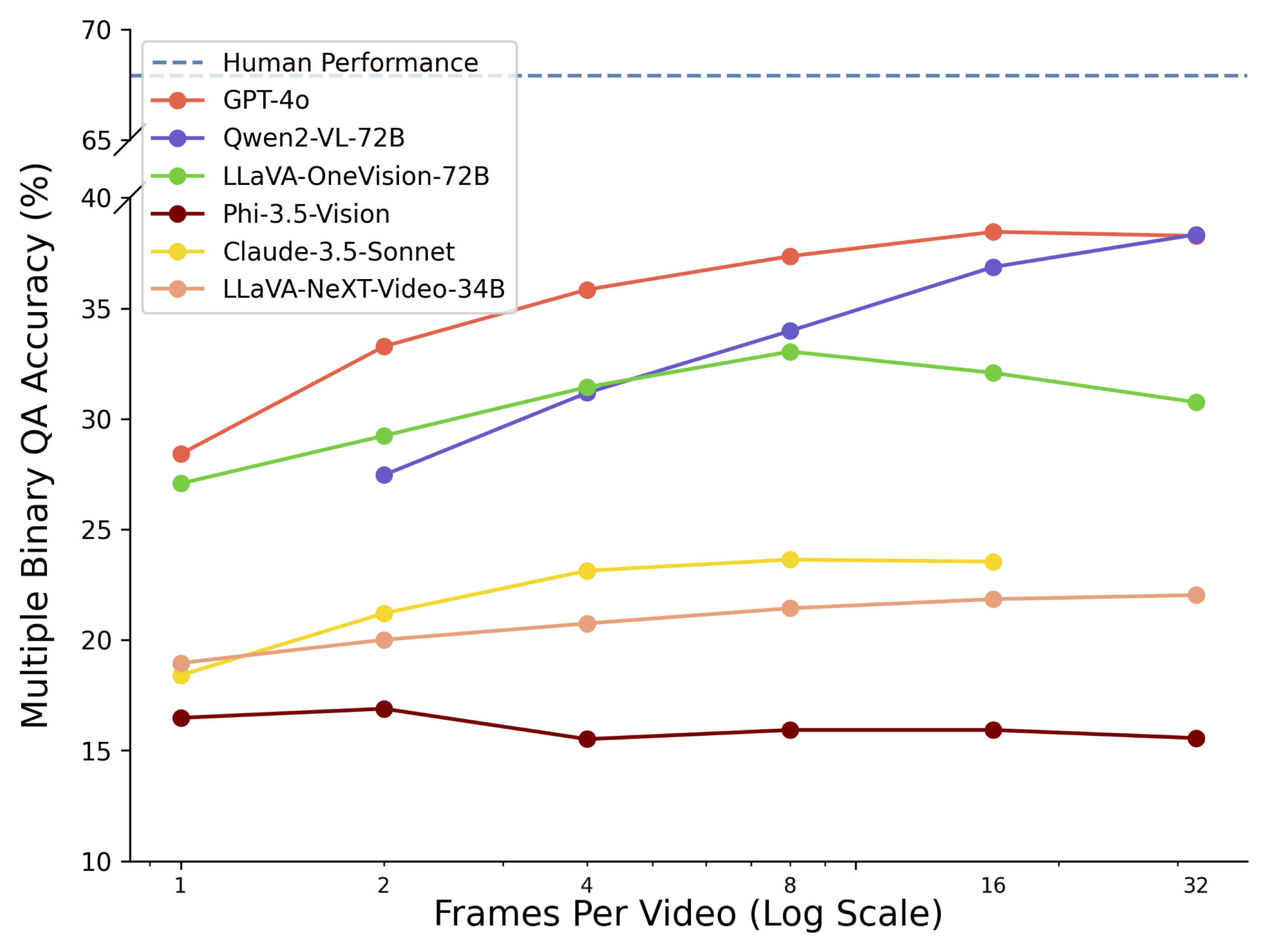
Accuracy scores on TemporalBench are presented for short video and long video question answering accuracy, reflected by both binary accuracy and multiple binary accuracy. Furthermore, we provide results on short video captioning. Overall QA denotes the average performance between
Short Video: [0,20] seconds Long Video: [0,20] minutes
The leaderboard is sorted by multiple binary accuracy on short videos by default. To view other sorted results, please click on the corresponding cell.
| # | Model | Frames | Date | Overall QA (%) | Short Video QA (%) | Long Video QA (%) | Detailed Captioning | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Multiple Binary Accuracy | Binary Accuracy | Multiple Binary Accuracy | Binary Accuracy | Multiple Binary Accuracy | Binary Accuracy | Similarity | ||||
| Human Performance | - | - | - | - | 67.9 | 89.7 | - | - | - | |
| Random Chance | - | - | 09.5 | 50.0 | 09.5 | 50.0 | 09.5 | 50.0 | - | |
| GPT-4o | 64 | 2024-06-15 | 35.3 | 73.2 | 38.0 | 76.0 | 32.7 | 70.5 | 63.5 | |
| GPT-4o | 32 | 2024-06-15 | 32.9 | 71.5 | 38.3 | 75.9 | 27.4 | 67.0 | 63.2 | |
| GPT-4o | 16 | 2024-06-15 | 34.3 | 72.8 | 38.5 | 75.7 | 30.1 | 69.8 | 61.3 | |
| Gemini-1.5-Pro | 1FPS | 2024-08-01 | 25.6 | 66.4 | 26.6 | 67.5 | 24.7 | 65.2 | 56.5 | |
| Claude-3.5-Sonnet | 16 | 2024-07-30 | 23.2 | 64.1 | 23.5 | 65.9 | 22.9 | 62.4 | 54.1 | |
| Claude-3.5-Sonnet | 8 | 2024-07-30 | 24.1 | 65.0 | 23.6 | 65.5 | 24.5 | 64.6 | 53.1 | |
| LLaVA-Video-72B | 32 | 2024-09-30 | 33.7 | 72.4 | 37.7 | 75.9 | 29.6 | 68.8 | 54.8 | |
| LLaVA-Video-7B | 32 | 2024-09-30 | 22.9 | 63.6 | 22.9 | 63.3 | 22.9 | 63.9 | 52.1 | |
| Aria | 32 | 2024-10-10 | 25.0 | 65.9 | 26.6 | 68.4 | 23.5 | 63.5 | 51.5 | |
| LongVU | 1FPS | 2024-10-22 | 18.9 | 58.5 | 20.9 | 61.7 | 16.9 | 55.3 | 40.5 | |
| Qwen2-VL-72B | 32 | 2024-06-15 | 31.7 | 70.2 | 38.3 | 75.8 | 25.0 | 64.5 | 56.1 | |
| Qwen2-VL-72B | 8 | 2024-06-15 | 30.1 | 68.9 | 34.0 | 73.1 | 26.2 | 64.7 | 51.4 | |
| Qwen2-VL-7B | 32 | 2024-06-15 | 21.7 | 62.0 | 24.7 | 64.4 | 18.8 | 59.7 | 51.9 | |
| LLaVA-OneVision-72B | 32 | 2024-08-08 | 26.6 | 66.6 | 30.7 | 70.5 | 22.4 | 62.7 | 53.9 | |
| LLaVA-OneVision-72B | 8 | 2024-08-08 | 28.1 | 67.8 | 33.0 | 72.1 | 23.1 | 63.6 | 55.0 | |
| LLaVA-OneVision-7B | 32 | 2024-08-08 | 18.7 | 59.4 | 21.2 | 61.9 | 16.2 | 56.9 | 50.1 | |
| LLaVA-NeXT-Video-34B | 32 | 2024-04-30 | 19.9 | 61.1 | 22.0 | 64.0 | 17.7 | 58.2 | 53.1 | |
| LLaVA-NeXT-Video-7B | 8 | 2024-04-30 | 20.5 | 61.2 | 23.6 | 65.1 | 17.3 | 57.2 | 50.1 | |
| InternLM-XC2.5 | 1FPS | 2024-04-30 | 16.7 | 57.3 | 17.9 | 58.8 | 15.6 | 55.8 | 52.4 | |
| VideoLLaVA | 8 | 2023-11-16 | 20.3 | 61.5 | 25.5 | 67.1 | 15.1 | 56.0 | 46.0 | |
| MiniCPM-V2.6 | 1FPS | 2024-08-12 | 20.4 | 61.3 | 21.4 | 62.3 | 19.3 | 60.3 | 47.2 | |
| Phi-3.5-Vision | 2 | 2024-08-16 | 15.5 | 56.2 | 16.9 | 58.0 | 14.1 | 54.4 | 42.9 | |
| MA-LMM | 4 | 2024-04-08 | 09.1 | 47.4 | 09.2 | 48.0 | 09.0 | 46.9 | 38.7 | |
| M3 | 6 | 2024-05-27 | 13.3 | 54.7 | 14.8 | 56.4 | 11.8 | 53.1 | 47.8 | |
| GPT-4o | 1 | 2024-06-15 | 26.4 | 67.3 | 28.4 | 70.0 | 24.5 | 64.7 | 52.3 | |
| LLaVA-1.5-13B | 1 | 2023-10-05 | 13.7 | 55.1 | 13.1 | 55.7 | 14.2 | 54.5 | 47.9 | |
| LLaVA-1.5-7B | 1 | 2023-10-05 | 15.3 | 56.8 | 18.3 | 60.5 | 12.3 | 53.2 | 45.7 | |
| LLaVA-NeXT-34B | 1 | 2024-01-30 | 19.0 | 60.5 | 18.0 | 60.5 | 19.9 | 60.5 | 49.1 | |
| Phi-3-Vision | 1 | 2024-05-19 | 15.4 | 55.2 | 15.1 | 54.4 | 15.6 | 56.0 | 42.0 | |